

On December 17, the Bright Minds, Cold Days workshop took place, bringing together 80 participants. During the event, attendees enjoyed a poster session featuring work by students from all public universities in Madrid, who had been invited by the ELLIS Madrid Unit.
Poster list
Exact Expressions for the Generalization Error of Statistical Federated Learning Algorithms
Abstract: In this paper, the generalization error of federated learning (FL) systems is characterized through a novel statistical framework. Central to this framework is the concept of a meta-federated learning algorithm, defined as a probability measure over a client’s local models conditioned on the datasets of all participating clients. By means of this abstraction, several fundamental properties of FL systems are stated and closed-form expressions for the generalization error are derived.
More specifically, the method of gaps, originally introduced for non-federated settings, is extended to FL, and closed-form expressions for the generalization error are obtained in terms of classical information measures, including relative entropy, mutual information, and lautum information. A central role in these new expressions is played by some specific Gibbs probability measures (Gibbs algorithms).
More importantly, it is revealed that the challenge of evaluating the generalization error in FL is reduced to two distinct tasks: (a) measuring the dependence of client model choices on the datasets of all clients; and (b) distinguishing the meta-federated learning algorithm from a Gibbs algorithm trained solely on local data. These findings establish new links between generalization in FL, mismatched hypothesis testing, Shannon’s information measures, and Pythagorean identities for the generalization error.
Author(s): Yaiza Bermudez, Samir M. Perlaza, Iñaki Esnaola, and H. Vincent Poor
Hyper-Transforming Latent Diffusion Models
Abstract: We introduce a novel generative framework for functions by integrating Implicit Neural Representations (INRs) and Transformer-based hypernetworks into latent variable models. Unlike prior approaches that rely on MLP-based hypernetworks with scalability limitations, our method employs a Transformer-based decoder to generate INR parameters from latent variables, addressing both representation capacity and computational efficiency. Our framework extends latent diffusion models (LDMs) to INR generation by replacing standard decoders with a Transformer-based hypernetwork, which can be trained either from scratch or via hyper-transforming—a strategy that fine-tunes only the decoder while freezing the pretrained latent space. This enables efficient adaptation of existing generative models to INR-based representations without requiring full retraining. We validate our approach across multiple modalities, demonstrating improved scalability, expressiveness, and generalization over existing INR-based generative models. Our findings establish a unified and flexible framework for learning structured function representations.
Authors: Ignacio Peis, Batuhan Koyuncu, Isabel Valera, Jes Frellsen
Robust-Multi-Task Gradient Boosting (R-MTGB)
Abstract: A boosting multi-task learning methodology that detects and adapts to outlier tasks. An innovative multi-task ensemble approach designed to model task heterogeneity directly within the gradient boosting framework
Authors: Seyedsaman Emami, Gonzalo Martínez-Muñoz, Daniel Hernández-Lobato
KT-Funnel: Accelerating Hyperparameter Tuning in Kernel Methods
Abstract: This work introduces KT-Funnel, a procedure to speed up hyperparameter tuning in kernel methods, along with an empirical evaluation of efficient cross-validation strategies for Kernel SVMs based on Kernel Thinning.
The goal is to reduce computational cost while maintaining predictive performance.
Results show that KT and KT-Funnel substantially accelerate tuning compared to standard cross-validation, achieving similar accuracy and improved stability in hyperparameter selection.
Authors: Blanca Cano Camarero
Abstract: Automatic detection of epileptic seizures in EEG requires models that are both accurate and interpretable. In this work, we evaluate entropy, information, and complexity (EIC) measures as input features for deep neural networks, comparing them with the usual time and frequency representations. We show that EICs consistently improve accuracy, sensitivity, specificity, and geometric mean across different architectures. Furthermore, we apply various explicable artificial intelligence (XAI) techniques to highlight the relevance of generalized entropies and Fisher information. These techniques reinforce the potential of deep neural networks in clinical applications supporting diagnosis.
Authors: Antonio Squicciarini, Mario Refoyo, David Luengo, Carlos E. Gonz ́alez-Guill ́en, Alejandro Zarzo
Automatic Screening of Parkinson’s Disease from Visual Explorations
Abstract: Eye movements can reveal early signs of neurodegeneration, including those associated with Parkinson\textquotesingle s Disease (PD). This work investigates the utility of a set of gaze-based features for the automatic screening of PD from different visual exploration tasks. For this purpose, a novel interpretable methodology is introduced, combining classic fixation/saccade oculomotor features (e.g., saccade count, fixation duration, scanned area) with features derived from gaze clusters (i.e., regions with a considerable accumulation of fixations). These features are automatically extracted from six exploration tests and evaluated using different machine learning classifiers. A Mixture of Experts ensemble is used to integrate outputs across tests and both eyes. Results show that ensemble models outperform individual classifiers, achieving an \ac{AUC} of 0.94 on a held-out test set. The findings support visual exploration as a non-invasive tool for early automatic screening of PD.
Authors: Maria Fernanda Alcala-Durand
Abstract: During the last years, the number of Internet of Things (IoT) devices has increased, and with it the exposure to different cyberattacks, making robust intrusion detection essential. Deep Neural Networks (DNNs) obtain strong performance in this field, but how they internally represent the data is still not well understood. Another challenge is the class imbalance in IoT data, which limits the model ability to learn minority attack types. The goal of this work is to study how a DNN organizes IoT attacks across its hidden layers, and how balancing the training dataset affects these internal representations. We trained a DNN with six hidden layers on four classes from the CICIoT2023 dataset. For each hidden layer, we extracted the activation matrices, projected them into 3D latent spaces, and analyzed them using inter-class distances. The model was trained both with the original unbalanced data and with a balanced version obtained by downsampling. The experiments show that deeper layers produce clearer and more separated manifolds. In the unbalanced case, the highest inter-class distance reached 38.73, while after balancing it increased to 61.01, showing much stronger separation between all attack classes. These results highlight the importance of balanced data for learning meaningful internal representations.
Authors: Estela Sánchez-Carballo, Francisco M. Melgarejo-Meseguer, José Luis Rojo-Álvarez
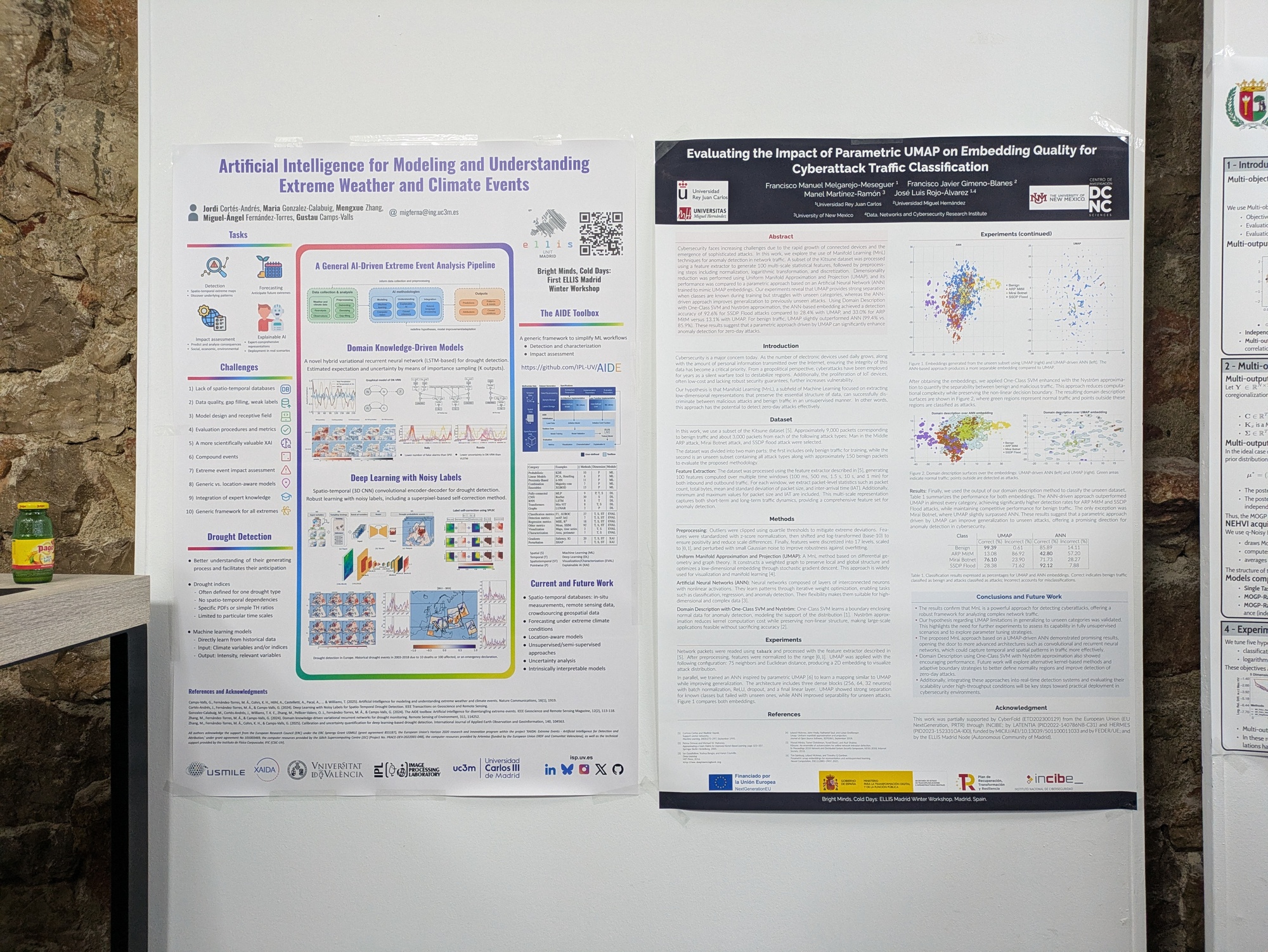
Artificial Intelligence for Modeling and Understanding Extreme Weather and Climate Events
Abstract: In recent years, Artificial Intelligence (AI) has significantly advanced Earth system sciences, including the prediction and analysis of extreme weather and climate events like floods, droughts, wildfires, and heatwaves. This domain faces specific challenges, such as developing accurate predictors from noisy, heterogeneous, small sample sizes, and data with limited annotations. The poster reviews how AI is applied to detection, forecasting, understanding, and impact assessment of extremes, emphasizing the need for accurate, transparent, and reliable models. We present a general AI-driven extreme event analysis pipeline and highlight specific challenges, including data scarcity, gap filling, model design, and achieving scientifically valuable Explainable AI (xAI). Examples include domain knowledge-driven models for drought detection using a hybrid variational recurrent neural network, and deep learning with noisy labels via a spatio-temporal convolutional encoder-decoder. We advocate for integrated AI solutions, like the AIDE Toolbox, that are practical, understandable, and trustworthy to enhance disaster readiness and risk reduction.
Authors: Jordi Cortés-Andrés, María González-Calabuig, Mengxue Zhang, Miguel Ángel Fernández-Torres, Gustau Camps-Valls
Detecting Behavioral Instabilities from Digital Phenotyping
Abstract: Foundation models have achieved remarkable success across various domains, yet their adoption in healthcare remains limited. While significant advances have been made in medical imaging, genetic biomarkers, and time series from electronic health records, the potential of foundation models for patient behavior monitoring through personal digital devices remains underexplored. The data generated by these devices are inherently heterogeneous, multisource, and often exhibit high rates of missing data, posing unique challenges. This paper introduces a novel foundation model based on a modified vector quantized variational autoencoder, specifically designed to process real-world data from smartphones and wearable devices. We leveraged the discrete latent representation of this model to effectively perform two downstream tasks, suicide risk assessment and emotional state prediction, on different held-out clinical cohorts without the need of fine-tuning. We also highlight the existence of a trade-off between discrete and continuous latent structures, suggesting that hybrid models may be optimal for balancing accuracy across various supervised and unsupervised tasks.
Authors: Josué Pérez Sabater Rodrigo Oliver Coimbra
Abstract: Deep Learning systems excel in complex tasks but often lack transparency, limiting their use in critical applications. Counterfactual explanations, a core tool within eXplainable Artificial Intelligence (XAI), offer insights into model decisions by identifying minimal changes to an input to alter its predicted outcome. However, existing methods for time series data are limited by univariate assumptions, rigid constraints on modifications, or lack of validity guarantees. This paper introduces Multi-SpaCE, a multi-objective counterfactual explanation method for multivariate time series. Using non-dominated ranking genetic algorithm II (NSGA-II), Multi-SpaCE balances proximity, sparsity, plausibility, and contiguity. Unlike most methods, it ensures perfect validity, supports multivariate data and provides a Pareto front of solutions, enabling flexibility to different end-user needs. Comprehensive experiments in diverse datasets demonstrate the ability of Multi-SpaCE to consistently achieve perfect validity and deliver superior performance compared to existing methods.
Authors: Mario Refoyo, David Luengo
Constraint-based learning of hybrid semi-parametric Bayesian networks
Abstract: Hybrid semi-parametric Bayesian networks have recently been proposed to model mixed data distributions with categorical, and continuous parametric and non-parametric nodes. Despite recent advances in conditional independence testing for mixed data, the learning of these Bayesian networks through constraint-based approaches remain unexplored, especially in settings where parametric assumptions break down. In this work, we show that there are statistically significant differences in structural accuracy and model likelihood between learning a hybrid semi-parametric Bayesian network under parametric or non-parametric assumptions, and that this is accentuated when the data follows mixed, non-Gaussian and non-linear distributions. We also present a method for inducing the model structure and continuous node types from a partially directed acyclic graph. Additionally, we propose a new implementation of non-parametric kNN-based tests for conditional independence with mixed data. We prove that choosing Vantage-Point trees as the data structure improves the computational complexity of estimating the conditional mutual information, and we accelerate the associated permutation test of conditional independence via moment matching.
Authors: Juan Fernández del Pozo Romero – Supervised by: Concha Bielza and Pedro Larrañaga
Decaflow: a deconfounding causal generative model
Abstract: We introduce DeCaFlow, a deconfounding causal generative model. Training once per dataset using just observational data and the underlying causal graph, DeCaFlow enables accurate causal inference on continuous variables under the presence of hidden confounders. Specifically, we extend previous results on causal estimation under hidden confounding to show that a single instance of DeCaFlow provides correct estimates for all causal queries identifiable with do-calculus, leveraging proxy variables to adjust for the causal effects when do-calculus alone is insufficient. Moreover, we show that counterfactual queries are identifiable as long as their interventional counterparts are identifiable, and thus are also correctly estimated by DeCaFlow. Our empirical results on diverse settings (including the Ecoli70 dataset, with 3 independent hidden confounders, tens of observed variables and hundreds of causal queries) show that DeCaFlow outperforms existing approaches, while demonstrating its out-of-the-box applicability to any given causal graph.
Authors: Alejandro Almodóvar, Adrián Javaloy, Juan Parras, Santiago Zazo, Isabel Valera
Evaluating the Impact of Parametric UMAP on Embedding Quality for Cyberattack Traffic Classification
Abstract: Cybersecurity faces increasing challenges due to the rapid growth of connected devices and the emergence of sophisticated attacks. In this work, we explore the use of Manifold Learning (MnL) techniques for anomaly detection in network traffic. A subset of the Kitsune dataset was processed using a feature extractor to generate 100 multi‐scale statistical features, followed by preprocessing steps including normalization, logarithmic transformation, and discretization. Dimensionality reduction was performed using Uniform Manifold Approximation and Projection (UMAP), and its performance was compared to a parametric approach based on an Artificial Neural Network (ANN) trained to mimic UMAP embeddings. Our experiments reveal that UMAP provides strong separation when classes are known during training but struggles with unseen categories, whereas the ANN-driven approach improves generalization to previously unseen attacks. Using Domain Description with One‐Class SVM and Nyström approximation, the ANN‐based embedding achieved a detection accuracy of 92.6% for SSDP Flood attacks compared to 28.4% with UMAP, and 33.0% for ARP MitM versus 13.1% with UMAP. For benign traffic, UMAP slightly outperformed ANN (99.4% vs. 85.9%). These results suggest that a parametric approach driven by UMAP can significantly enhance anomaly detection for zero‐day attacks.
Authors: Francisco Manuel Melgarejo-Meseguer, Francisco Javier Gimeno-Blanes, Manel Martínez-Ramón, José Luis Rojo-Álvarez
Topological Analysis of Feature Importance and Relations (TAFIR)
Abstract: Understanding which features shape the structure of a dataset, and how they interact, remains a central challenge in explainable machine learning. Current approaches typically rely on model-dependent importance estimators or local attribution methods, limiting their capacity to reveal the global organization of the data. We introduce Topological Analysis of Feature Importance and Relations (TAFIR), a novel model-agnostic methodology that uses the topological graph induced by UMAP as a computational scaffold for analyzing feature behavior. TAFIR operates in two complementary modes. In the unsupervised mode, the method quantifies the variation of each feature across graph connections to identify the core dimensions that define the intrinsic geometry of the data, as well as the strength of linear and non-linear feature relationships. In the supervised mode, the edges of the graph are decomposed into intra-class and inter-class connections, allowing the identification of features and interactions that are particularly relevant for discrimination. We validate TAFIR on a controlled synthetic dataset with known ground truth, demonstrating its ability to recover the true manifold structure, filter irrelevant noise variables, and highlight synergistic interactions critical for classification. TAFIR provides a transparent and interpretable framework to study feature importance and relationships from a topological perspective.
Authors: Luis Bote-Curiel, Ismael Gómez-Talal, Giuseppe Casalicchio, José Luis Rojo-Álvarez
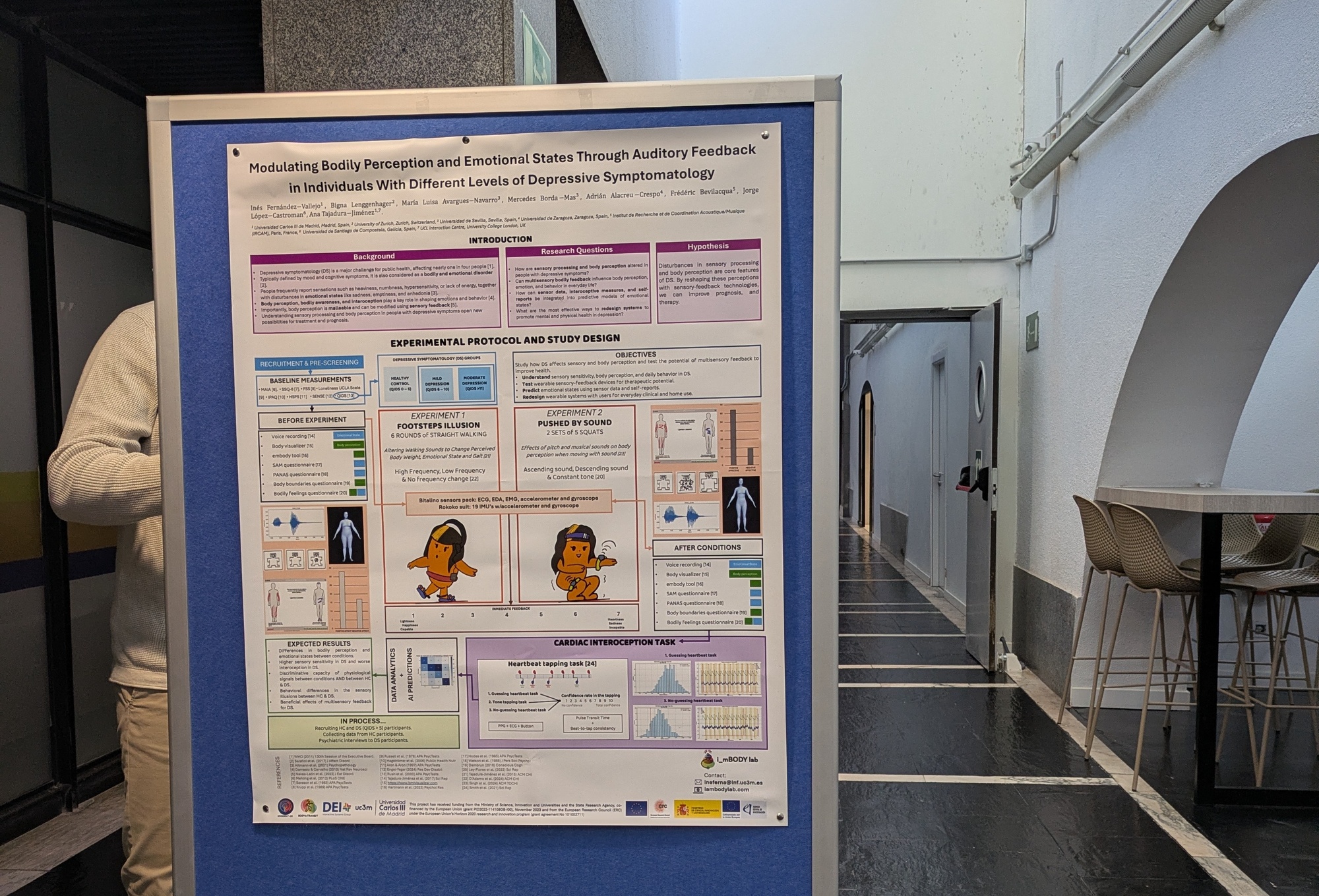
Abstract: Altered bodily and sensory perception, as well as interoceptive awareness, are increasingly recognized as key factors in affective disorders such as depression. People with depressive symptoms often describe bodily heaviness and show reduced interoceptive accuracy. This study investigates the short-term malleability of bodily perception and emotional states in response to sensory-driven bodily illusions in individuals with depressive symptoms compared to healthy controls. We use two auditory-based illusions associated with sensations of bodily lightness or heaviness: the “Footstep Illusion,” which alters footstep sounds to evoke changes in perceived body weight and emotional valence, and the “Auditory Pinocchio Illusion,” where movements are paired with ascending or descending pitch to elicit sensations of ease or difficulty, as well as positive or negative emotions. Throughout the experiments, we will record body perception measures, gait biomechanics, physiological signals, voice features, and self-reported emotional states. Participants will also complete a heartbeat tapping task and questionnaires assessing interoceptive awareness and sensory processing sensitivity. All collected physiological and vocal data will later be analyzed with artificial intelligence methods to develop predictive models of emotional and bodily state changes. We hypothesize that individuals with depressive symptoms will show distinct responses to sensory-induced bodily illusions, reflecting altered bodily self-representation and interoceptive processing. This research aims to advance understanding of brain–body dynamics in depression and support the development of novel embodied intervention.
Authors: Inés Fernández−Vallejo, Bigna Lenggenhager, María Luisa Avargues−Navarro, Mercedes Borda −Mas, Adrián Alacreu −Crespo, Frédéric Bevilacqua, Jorge López−Castroman, Ana Tajadura−Jiménez.
Why Do Models Fail Across Hospitals? Understanding and Mitigating Domain Shift in MALDI-TOF MS
Abstract: MALDI-TOF mass spectrometry enables rapid bacterial identification through spectral fingerprints.
However, spectra collected across hospitals differ due to variations in instruments, calibration, and
preprocessing, creating domain shifts that limit model transferability. As a result, models trained on
data from one hospital often fail to generalize to others, even for the same bacterial species.
In this work, we explore and visualize inter-hospital domain discrepancies using t-SNE projections of
spectral embeddings, revealing clear site-specific clusters. We further investigate VAE-based
approaches to learn domain-invariant latent representations, including multi-decoder VAEs and
conditional VAEs, aiming to separate biological variability from acquisition bias. Complementary
alignment strategies such as DANN, and CycleGAN are considered.
Our ongoing experiments highlight the persistent impact of acquisition heterogeneity on spectral
structure and motivate the development of adaptable, domain-aware learning frameworks for
reliable MALDI-TOF-based diagnostics across hospitals.
Authors: Alejandro L. García Navarro, Lucía Schmidt Santiago, Carlos Sevilla Salcedo, Vanessa Gómez Verdejo
AI-driven Generation of MALDI-TOF MS for Microbial Characterization
Abstract: Matrix-Assisted Laser Desorption/Ionization Time-of-Flight Mass Spectrometry (MALDI-TOF MS) is central to modern clinical microbiology, yet the development of data-driven diagnostic tools is hindered by the scarcity and imbalance of publicly available spectral datasets. This work explores deep generative modeling as a solution to these limitations by synthesizing realistic microbial spectra for machine learning applications. We adapt and evaluate three conditional generative models, Variational Autoencoders (MALDIVAE), Generative Adversarial Networks (MALDIGAN), and Denoising Diffusion Probabilistic Models (MALDIffusion), to generate spectra conditioned on microbial species. We assess the fidelity and diversity of the generated data using statistical comparisons, structural similarity metrics, and downstream classification performance. Our results show that synthetic spectra produced by the three models are both statistically coherent and diagnostically informative. Classifiers trained exclusively on synthetic data achieve performance close to those trained on real measurements. MALDIffusion produces high-fidelity spectra but at a significant computational cost, while MALDIGAN yields realistic but slightly less stable outputs. MALDIVAE provides the best overall trade-off, offering consistent, efficient generation with strong spectral realism. Additionally, augmenting minority species with synthetic samples improves classification accuracy and mitigates class imbalance without compromising data authenticity.
Authors: Lucía Schmidt-Santiagoa, David Rodríguez-Temporal, Carlos Sevilla-Salcedo, Vanessa Gómez-Verdejo
Multimodal Posterior Sampling-based Uncertainty in PD-L1 Segmentation from H&E Images
Abstract: Accurate assessment of PD-L1 expression is essential for guiding immunotherapy, yet standard immunohistochemistry (IHC) pipelines remain slow and resource-intensive. We introduce nnUNet-B, a Bayesian extension of nnUNet-v2 that infers PD-L1 expression directly from H&E-stained histology and produces pixel-wise uncertainty estimates to support interpretability. Our framework leverages Multimodal Posterior Sampling (MPS): diverse checkpoints obtained through cyclic training are sampled to approximate the posterior distribution over model weights. This enables both robust segmentation and epistemic uncertainty quantification using entropy and standard deviation. We evaluate nnUNet-B on a lung squamous cell carcinoma cohort, achieving mean Dice = 0.805 and mean IoU = 0.709, competitive with strong baselines. Uncertainty maps consistently highlight regions prone to segmentation error, demonstrating a strong correlation between uncertainty and model failure, although overall calibration remains imperfect. These findings suggest that uncertainty-aware PD-L1 prediction from routine H&E slides is feasible and may support scalable biomarker assessment in settings where IHC is costly or unavailable. Our approach provides a promising step toward reliable, interpretable, and more accessible PD-L1 quantification in clinical workflows.
Authors: Roman Kinakh
Segmentation of Arabidopsis Apical Stem Cells via a Dual Deep Learning Approach
Abstract: We introduce a deep learning pipeline for segmenting apical stem cells in three-dimensional confocal microscopy volumes of Arabidopsis thaliana. By integrating pre-trained 2D and 3D U-Net models from the BioImage Model Zoo , our method combines in-plane boundary sharpness with volumetric continuity. The workflow encompasses parallel preprocessing, dual-model inference, logical fusion, and membrane-aware post-processing to extract key morphometric features, including cell counts and volumes. Evaluated over 22 timepoints using Passing–Bablok regression, our approach yields a cell count slope of 0.885, surpassing both the standalone 2D U-Net (0.539) and 3D U-Net (0.782) models. Additionally, our approach successfully replicates reported growth pulses, confirming its validity for dynamic analysis. These results highlight the advantages of model fusion for robust, high-fidelity segmentation. Code availability: https://github.com/GolpedeRemo37/Arabidopsis_DualDL
Authors: Guillermo Rey-Paniagua, Dariusz Lachowski, and Arrate Muñoz-Barrutia
Impact of Evaluation Noise in the Context of Multi-objective Bayesian Optimization
Abstract: Multi-objective Bayesian optimization (MOBO) is a powerful framework for optimizing black-box functions with conflicting objectives and costly evaluations. A key component in MOBO is the probabilistic surrogate model used to guide the search for the optimum, which in practice is most often implemented using independent Gaussian processes (GPs), one per objective. A less common but more powerful approach is to use multi-output GPs to exploit correlations between objectives. However, with this model, independent observation noise across objectives is typically assumed, which ignores part of the correlation structure. In this work, we focus on multi-output GPs that can also capture correlations in the observational noise, and study how the presence and structure of noise affect the joint predictive distribution, the NEHVI acquisition function, and ultimately the optimization performance. Through theoretical analysis and extensive synthetic and real-world experiments, we show that multi-output GPs can improve optimization efficiency when evaluations are noisy. Importantly, however, when the evaluations are noiseless, we observe, both theoretically and empirically, only small gains by using multi-output GPs, and cheaper independent GPs are preferred. Furthermore, our synthetic experiments show that explicitly modeling noise correlations provides additional advantages when the objectives themselves are negatively correlated. On the other hand, in real-world experiments, where model bias may be relevant, we observe that modeling noise correlations has little impact on the optimization results. These findings provide practical insights into when and how to use multi-output GP models in the context of MOBO.
Authors: Daniel Fernández-Sánchez, Carlos Sevilla-Salcedo, Vanessa Gómez-Verdejo,Daniel Hernández-Lobato
Unraveling Attack Topology: Representation Learning on Graphs for Network Security
Abstract: The study addresses IoT security visualization by comparing latent space representations in Graph Deep Learning models. It evaluates two specific architectures: Homogeneous and Heterogeneous Graph Neural Networks (GNNs) using the CIC-IoT-2023 dataset.
High-dimensional embeddings data is projected into low-dimensional spaces to show how graph topology organizes network flows and devices. The analysis reveals distinct structural differences in cluster formation and class separation between the two GNN approaches.
Authors: Enrique Feito-Casares, Francisco M. Melgarejo-Meseguer, Elena Casiraghi, Giorgio Valentini, José-Luis Rojo-Álvarez
Abstract: Here, we study how different feature sources (or modalities) can predict which individuals will develop mild cognitive impairment (MCI). Data of 934 participants from the Vallecas project, cognitively normal at baseline, were used: 113 developed MCI during the 9 follow-up visits (converters), and 821 were taken as controls. Thus, this analysis simultaneously predicts MCI conversion in the next year, in two years, …, up to 9 years.
An initial set of 742 features from 9 modalities, all measured at the first visit, was considered. A logistic regression regularized with an elastic net was used to parsimoniously select groups of features. The analysis was repeated for each feature source combination independently. Repeated nested cross-validation was used for model assessment and hyperparameter tuning via Bayesian optimization, thereby addressing the risk of data leakage and overfitting. The dataset was split 7 times into 25 folds across the two levels.
The best performing models achieve an AUC of ~0.75. Cognitive examination and the brain MRI analysis with the SPM software provided the best performance on their own. The worst performing sources were typical parameters included in visual neuroradiological reporting, and the neurological examination. Overall, memory performance, genetic factors (like APOE and polygenic risk scores), and patters of atrophy in the entorhinal cortex, amygdala and hippocampus were the most important predictors.
Authors: Pablo Bonilla-Escribano, Linda Zhang, Teodoro Del Ser, Pascual Sánchez-Juan, Jussi Tohka and Bryan Strange.
Incremental constraint-based causal discovery
Authors: José M. De Miguel, Concha Bielza, Pedro Larrañaga
Unmasking Alzheimer’s: a Self-Supervised MRI AEM Model
Authors: Nuria Balbás, Albert Belenguer-Llorens, Jussi Tohka, Vanessa Gómez-Verdejo, Carlos Sevilla-Salcedo
Optimal transport group counterfactual explanations
Abstract: Group counterfactuals explanations find a group of counterfactual instances in order to contrastively explain a group of input instances. However, existing methods either (i) optimize counterfactuals only for a fixed cohort and do not generalize to new group members, or (ii) rely on strong model assumptions (e.g., linear or linearizable classifiers) for tractability. We instead learn an explicit optimal transport map that sends any group instance to its counterfactual without re-optimization, minimizing the group’s total transport cost. This approach allows for generalization, more interpretability and a significant reduction in the number of parameters to be optimized, which is crucial in scenarios where non-linear black box models are considered. Experiments show that functions derived through mathematical optimization when linear models are considered can be generalized correctly for new instances, with an increase in transport cost that is negligible compared to a baseline method. In cases where the linearity of the model cannot be exploited, our proposal greatly outperforms the baseline.
Authors: Enrique Valero-Leal, Bernd Bischl, Pedro Larrañaga, Concha Bielza, Giuseppe Casalicchio
Bandwidth Selectors on Semiparametric Bayesian Networks
Abstract: Semiparametric Bayesian networks (SPBNs) rely on Kernel Density Estimators to model
flexible, non-linear conditional distributions. Current implementation relies on the Normal Rule bandwidth selector—a simple but restrictive choice rooted in Gaussian assumptions. When real-world data departs from normality, this leads to oversmoothed and biased non-parametric estimations, limiting predictive performance.
We provide the theoretical framework for guaranteeing the performance under these bandwidth selectors.
We propose the integration of Plug-in and Cross-validation bandwidth selectors, offering adaptive and data-driven strategies better suited to the context.
These methodologies improve the estimation of non-Gaussian conditional density distributions, enhancing the modeling capacity of SPBNs.
Authors: Victor Alejandre, Concha Bielza and Pedro Larrañaga